Giới thiệu một qui trình hoàn chỉnh về xây dựng mô hình khai phá dữ liệu
Nguyễn Văn Chức - chucnv@ud.edu.vn
Trong các bài viết trước, tôi đã giới thiệu các kỹ thuật, qui trình cũng như cách thức xây dựng các mô hình khai phá dữ liệu (Data mining Model -DMM). Tuy nhiên, qua nhiều phản hồi của các bạn đọc thì rất nhiều ý kiến hỏi về cách sử dụng DMM trong việc dự đoán dữ liệu chưa biết (unseen data) như thế nào cũng như quá trình xây dựng và sử dụng một DMM đầy đủ các bước như thế nào?
Bài viết này giới thiệu thực hiện một DMM với đầy đủ 4 công việc chính của quá trình khai phá dữ liệu đó là: 1. Chuẩn bị dữ liệu (Data preparation); 2. Xây dựng mô hình (Data Modeling); 3. Đánh giá mô hình (Validation); 4. Sử dụng mô hình để dự đoán dự liệu trong tương lai (Model Usage)
Mô tả dữ liệu sử dụng trong bài viết
Dữ liệu được dùng là Data source gồm 10.000 khách hàng của hãng sản xuất xe đạp Adventureworks, gồm 13 thuộc tính như sau. (Đây là dữ liệu điều tra khách hàng của công ty Adventureworks. (download dataset tại đây)
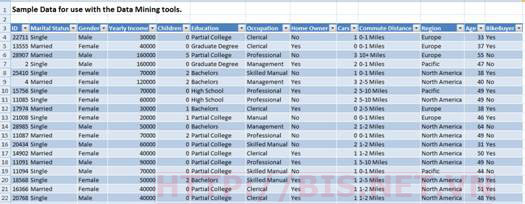
Mục đích là mô tả quá trình đầy đủ về xây dựng một DMM phân lớp khách hàng vào 2 lớp là có mua xe đạp hay không (thuộc tính Bikebuyer = Yes hay No) để dự đoán khả năng mua xe đẹp của khách hàng. Công việc này được thực hiện thông qua 4 giai đoạn: Data preparation; Data Modeling; Validation; Model Usage.
Công cụ sử dụng là SQL Server Business Intelligence Development Studio (Add –ins trong MS Excel 2007)
1. Chuẩn bị dữ liệu cho mô hình (Data Preparation)
Trong bước này chúng ta thực hiện các công việc tiền xử lý dữ liệu theo yêu cầu của mô hình như trích chọn thuộc tính, rời rạc hóa dữ liệu (các vấn đề này đã đề cập ở các bài viết trước) và cuối cùng là chia dữ liệu nguồn (Data Source) thành 2 tập dữ liệu dùng để huấn luyện mô hình (Training Data) và kiểm tra mô hình (Testing data).
Bây giờ từ Data source ban đầu (10.000 Records) ta tạo ra Training Data (70%) và Testing Data (30%) như sau:
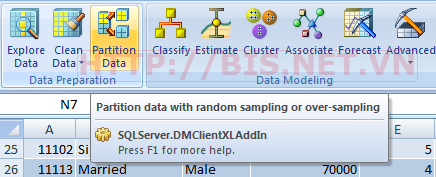
Chọn Partition Data →Next→Chọn Data Source →Split Data into train and Test sets→ Chọn 70% cho Training Set
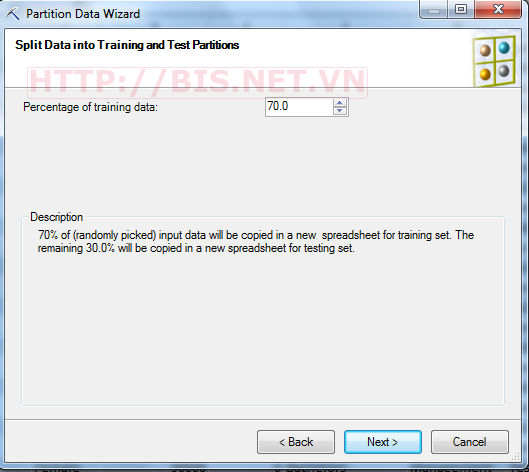
Đặt tên cho Training and Testing Data → Finish
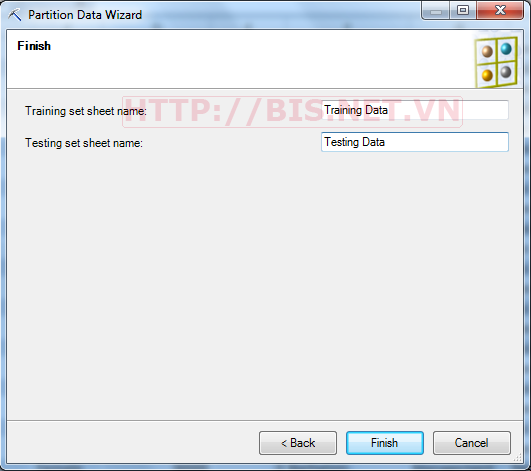
Sau bước chuẩn bị dữ liệu ta có 2 sheet chứa dữ liệu để huấn luyện DMM là Training Data với 7000 khách hàng (70%) và dữ liệu để kiểm tra DMM là 3000 khách hàng (30%)
2. Xây dựng mô hình (Data Modeling)
Trong bước này ta sử dụng Training Data vừa tạo ra để xây dựng mô hình, trong ví dụ này sử dụng mô hình cây quyết định phân lớp.
Trong Menu Advanced→Create Mining Model→Next

Chọn nguồn dl là Training Data→Next→Chọn Microsoft Decision Tree→Next
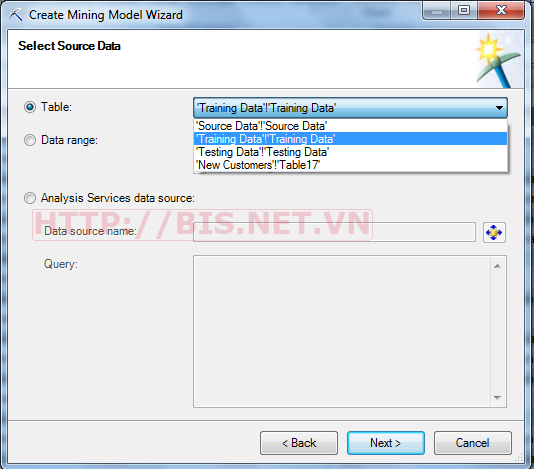
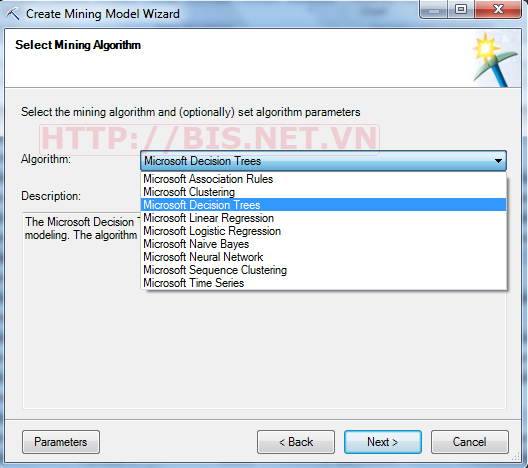
Xác định thuộc tính khóa là ID và thuộc tính phân lớp là BikeBuyer

Bấm Next →Đặt tên cho Structure name và Model name →Finish
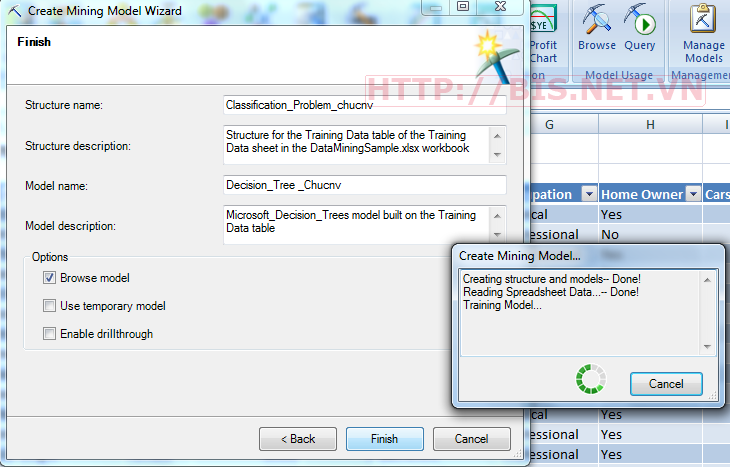
Kết quả mô hình như sau:

3. Kiểm định mô hình (Validation model)
Sau khi sử dụng Training Data để xây dựng mô hình, bây giờ ta sử dụng Testing Data để kiểm tra xem mô hình có đủ tốt để sử dụng hay không? (Nếu chưa đủ tốt thì phải sử dụng Training Data khác để huấn luyện lại)
Có 3 kỹ thuật chính để kiểm tra mô hình đó là sử dụng Accuracy Chart (Lift Chart), Classification Matrix và Profit Chart.

Chọn Accủacy Chart→Next→Chọn Mô hình cần kiểm tra →Next
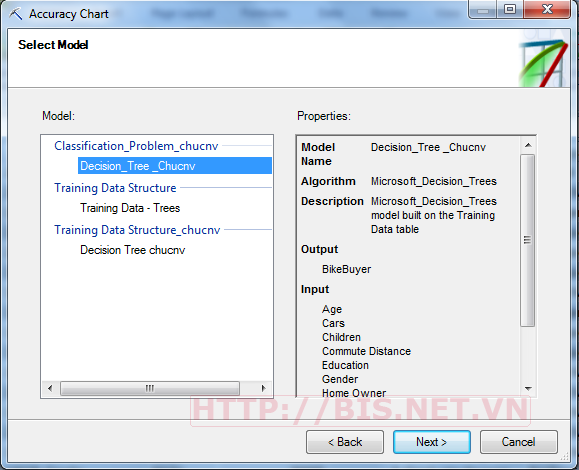
Chọn Next và chọn thuộc tính phân lớp BikeBuyer và giá trị dự đoán Yes (mua xe)

Bấm Next → Chọn dữ liệu để Test Mô hình

Bấm Next→Thiết lập quan hệ giữa các thuộc tính trong Model với các thuộc tính trong Testing Data.
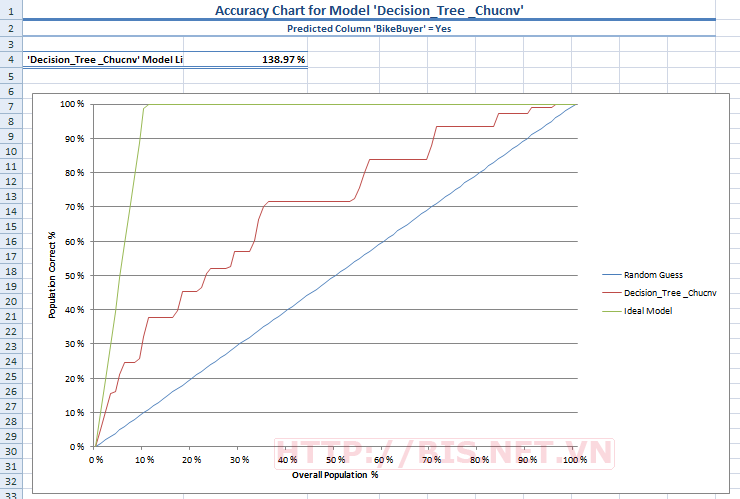
Bấm Finish để kết thúc. Kết quả Lift Chart như sau:
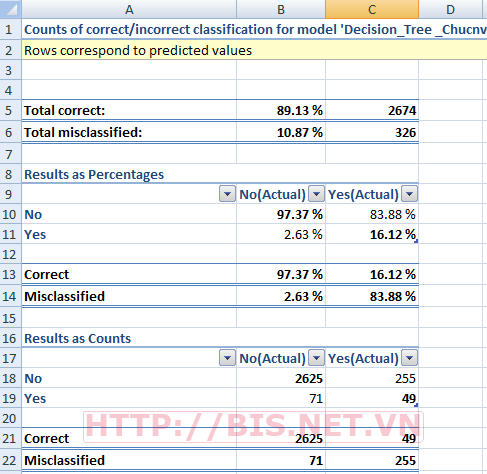
Tương tự các bước như đã làm với Accuracy Chart nhưng nếu chọn Classification Matrix thì kết quả như sau
Profit Chart của Model
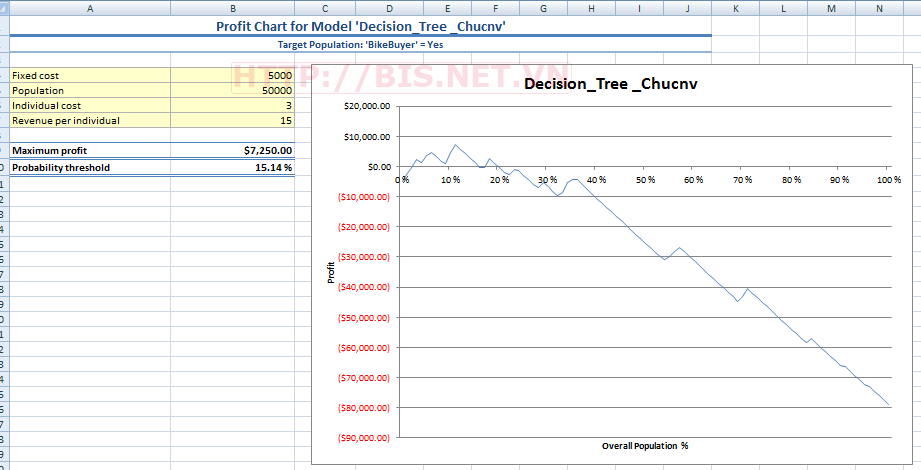
Trong mô hình cây quyết định đã xây dựng, độ chính xác đạt 89.13% và profit chart cho biết lợi nhuận thu được lớn nhất khi $7250 khi sử dụng 11% Testing data.
(Để biết cách sử dụng Lift Chart và Classification Matrix và profit chart để đánh giá Data Mining Model xem chi tiết tại bài viết này tại http://bis.net.vn/forums/t/476.aspx)
4. Sử dụng mô hình (Model Usage)
Sau khi mô hình được kiểm tra (Testing) nếu độ chính xác đáp ứng yêu cầu thì có thể sử dụng model đã xây dựng vào dự đoán các dữ liệu chưa biết. Bây giờ ta sẽ sử dụng mô hình phân lớp cây quyết định đã xây dựng để dự đoán các khách hàng có mua xe đạp của công ty không? Dữ liệu cần dự đoán trong sheet “New Customers” có 77 khách hàng (chú ý rằng dữ liệu khách hàng này không có thuộc tính BikeBuyer vì đây là dữ liệu tương lai cần dự đoán và các khách hàng này không xuất hiện trong Training và Testing Data)

Bây giờ ta sẽ dùng Mô hình khai phá dữ liệu cây quyết định đã xây dựng để dự đoán khách hàng nào có khả năng mua hay không mua xe đạp tại công ty (Thuộc tính BikeBuyer = Yes hay No)
Chọn Query trên Menu
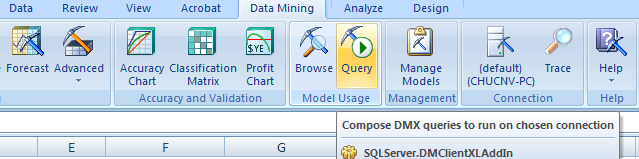
Chọn Next→Chọn Data Mining Model đã xây dựng
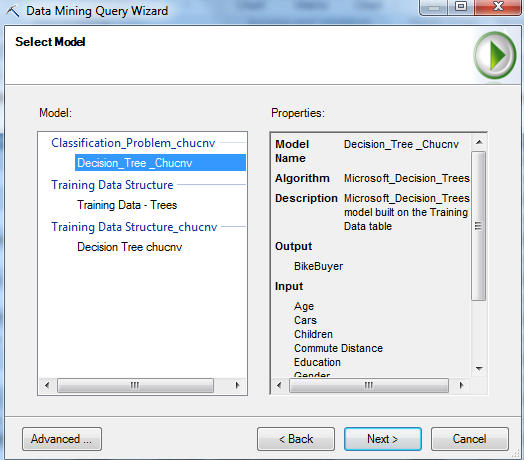
Chọn Next và chọn dữ liệu cần dự đoán (phân lớp), ở đây là bảng dữ liệu New Customers
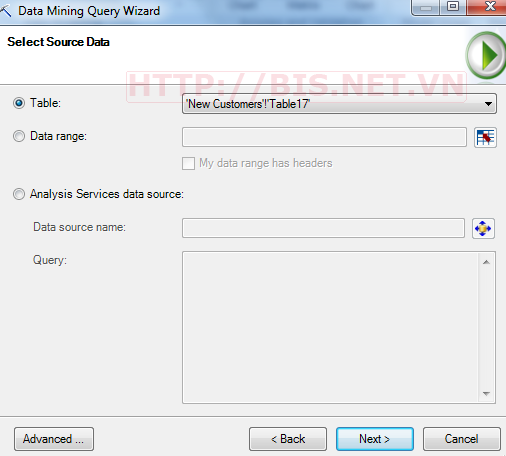
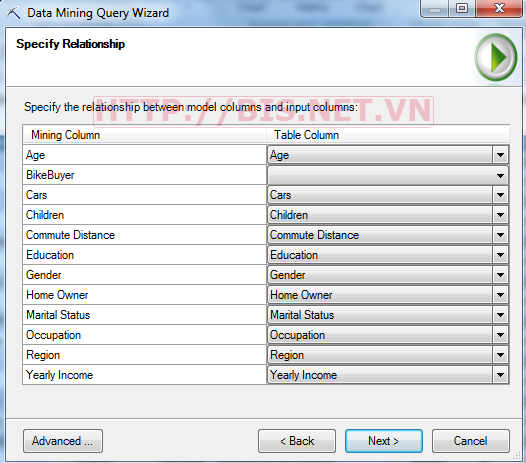
Chọn Next →Thiết lập quan hệ giữa các thuộc tính trong Model với các thuộc tính trong dữ liệu cần dự đoán
Bấm Next →Chọn Add Output để xác định các thuộc tính sinh ra ở bảng kết quả. Ở đây chọn 2 thuộc tính là ID và thuộc tính dự đoán phân lớp là BikeBuyer

Chọn New worksheet để kết quả dự đoán tạo ra một sheet mới và bấm Finish để hoàn thành. Kết quả dự đoán (phân lớp) khách hàng như sau:
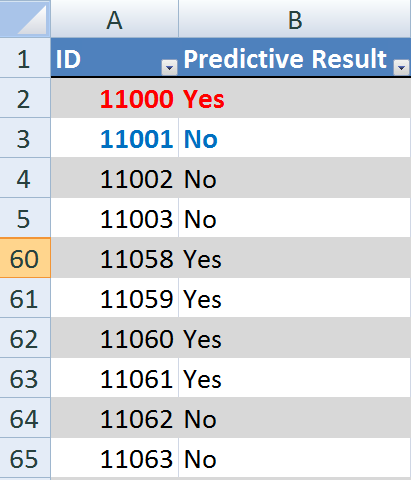
Trong kết quả dự đoán này, khách hàng có ID là 11000 có khả năng mua xe đạp của công ty (khách hàng tiềm năng) và khách hàng có ID 11001 được dự đoán là không mua hàng của công ty. Chúng ta có thể đưa ra nhiều thông tin về khách hàng hơn bằng việc chọn Add Output và thêm các thuộc tính về khách hàng.
Ngoài việc phân lớp các khách hàng, mô hình còn có thể dự đoán xác suất tương ứng với từng giá trị của thuộc tính phân lớp. Ví dụ như ta muốn dự doán xác suất các khách có khả năng mua hàng (Giá trị thuộc tính BikeBuyer = Yes), thiết lập như sau:
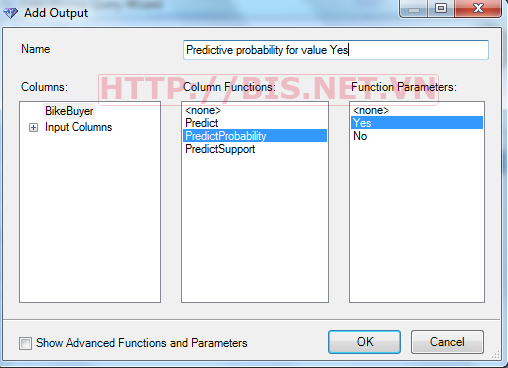
Kết quả như sau:
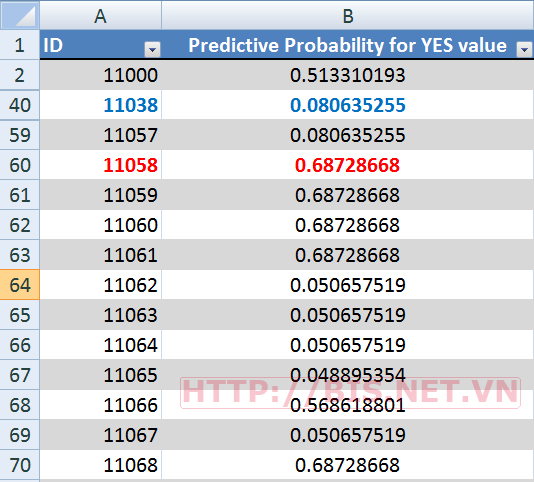
Với kết quả trên, khách hàng có ID là 11058 có xác suất mua hàng là 0.68728668 (>0.5) nên được xếp vào lớp mua hàng (BikeBuyer = Yes) và khách hàng có ID là 11038 có xác suất mua hàng là 0.080635255(<0.5) nên được xếp vào lớp không mua hàng (BikeBuyer = No).
Theo bis.net.vn
Tình huống đặt ra là Sinh Viên khiếu nại việc phân bổ ngân sách hiện tại không hợp lý, đó là nó đang dựa trên số liệu đã cũ về sở thích tham gia hoạt động của sinh viên. Dẫn đến những hoạt động mới hiện tại sinh viên quan tâm thì lại không đc rót kinh phí phù hợp (điều này nguyên nhân có thể là do hoạt động mới thì chưa/ít có số liệu lịch sử). -->Dẫn đến tình trạng ngân sách được sử dụng không đúng chỗ, lãng phí.
*** Yêu cầu là sử dụng Reporting or/and Data Mining System để đánh giá khiếu nại này.
- Số liệu lịch sử hoạt động từ các năm trước sẽ có thể có những gì? Có thể dùng reporting system/datamining system như thế nào để có đc thông tin mình muốn và đánh giá khiếu nại này có đúng hay không?